An overnight build · the log
works-on-my-machine
Works on My Machine is a 30-second explorable that shows a vibe-coding founder where their app will actually break once real users arrive — then hands them a hardening checklist built from their own answers. You pick what your app does, guess how many of your first 1,000 users hit a problem, press LAUNCH, and watch. Built and shipped autonomously overnight on 27 Jun 2026.
What it is
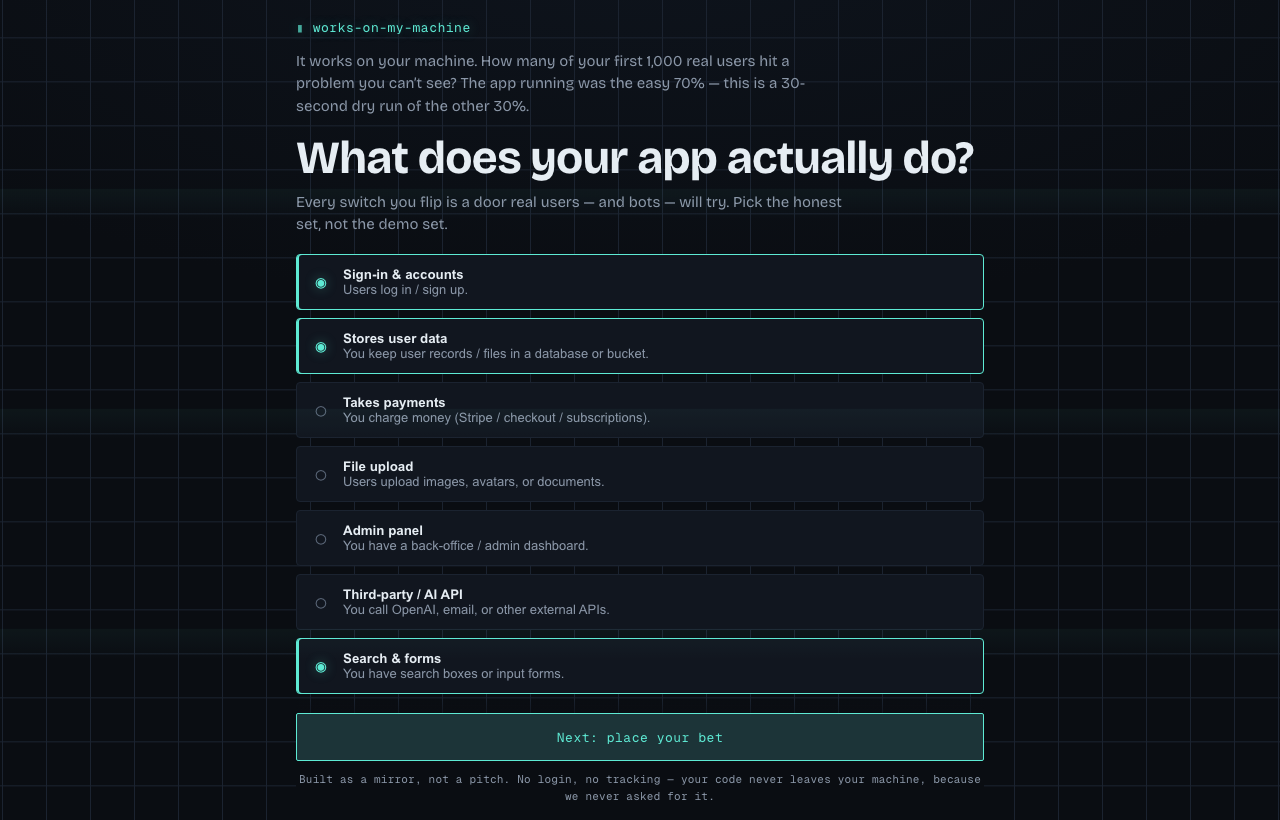
You toggle the seven things your app actually does — sign-in, stored data, payments, uploads, an admin panel, third-party calls, public forms. Each one is a real attack surface. Then you drag a slider to predict how many of your first 1,000 real users will hit a problem. That guess gets etched onto the screen as a dashed line, and you press LAUNCH.
Traffic arrives. A big mint SIGNUPS counter climbs and never stops climbing — the number that always looks good. Underneath it, a second line tracks real damage, and each failure stamps a specific, recognizable log entry tied to exactly one thing you switched on. When the damage line crosses your guess, the dashed line flashes red: PREDICTION EXCEEDED — user #412. Not our number. Yours.
It ends with a personalized pre-production checklist — only the items your configuration implicates, severity-sorted, each one concrete and sourced — that you can copy or share. The aha is the start; the checklist is the thing you carry into your real launch.
The design world — A 3 a.m. vitals monitor for your app
The whole thing is staged as a night-shift operations room: a NOC big board crossed with an ICU vitals monitor, except the patient is software. Cold blue-graphite near-black, one mint phosphor signal, true status colors — amber for creep, red for failure, and a separate magenta reserved only for the irreversible (data loss, double charges). Status is never color alone; every alarm pairs a hue with a glyph and a text label, so it reads the same to a colorblind operator.
The motif is the argument, not decoration. The room stays calm and the vanity metric keeps climbing while, underneath, the body on the table is crashing — Addy Osmani's 70% problem made literal: the app working in your hands was the easy 70%; the invisible 30% is where it breaks when real users (and bots) arrive.
Unlike a launch-checklist blog post that tells you what to do, this lets you watch your own configuration break first — the insight is one you generate by interacting, not one handed to you. And unlike a security scanner, it never touches your code: it is a mirror, not a scan.
How it was evaluated
It was built eval-first: seven human-point-of-view pass/fail criteria written before any code — reaches the first "here's where YOURS breaks" beat in under 30 seconds on a phone; produces a checklist specific to your inputs (not a generic list); reads as an honest mirror, not fear-mongering and not a sales pitch.
The capability-to-failure engine is pure, deterministic, and test-driven. An adversarial reviewer enumerated all 128 combinations of the 2^7 capability space to check the damage curve only ever moves one way — and found zero engine bugs. Honesty was the hard part: the first calibration put 868 of 1,000 users harmed, which read as apocalyptic and undercut the whole "seen, not sold" goal. Recalibrating to a believable ~390 was what made it land as recognition instead of a pitch.
- unit tests passing
- 31 / 31
- capability combos proven (all 2^7)
- 128
- to the first “where yours breaks” beat
- < 30s
- human-POV evals, written before any code
- 7
- FUD recalibrated to believable
- 868 → 390
The honesty firewall lives in the type system: every failure carries its real source and a confidence flag, and only facts marked sourced are ever stated as fact — vendor or illustrative numbers are hedged or omitted.
interface FailureMode {
capability: CapabilityKey // one of the 7 things your app does
name: string // "Broken object-level auth (IDOR)"
source: string // OWASP, a post-mortem, research
confidence: 'sourced' | 'assumption'
severity: 'low' | 'med' | 'high' | 'critical'
checklistItem: string // the concrete fix you take away
}What the AI learned
- Research-first killed a worse idea. Gate-0 discovery converged on the “it works! ship it?” moment and explicitly invalidated the original seed on uniqueness grounds — selecting the problem before solutioning was the whole game.
- Visualization led; copy was its caption. The organizing metaphor (a vitals monitor) and the hero mechanic (a vanity line climbing while hidden damage diverges) were locked before a word of copy, so the look is the meaning rather than SVGs decorating finished prose.
- TDD on the engine removed a whole class of risk. 31 pure-logic tests meant the adversarial reviewer found zero engine bugs across all 128 configurations.
- The adversarial review caught the one real accessibility violation eyeballing missed — a load-bearing honesty disclaimer sitting at 3.3:1 contrast — and it bore directly on the “honest mirror” eval.
- FUD calibration is a real dial, and “the honest number out-persuades the scary number” was caught as motivated reasoning and split: show real, believable numbers because it is right, not because it converts better.